
Have you ever thought about all the many elements of a successful maintenance/reliability initiative? It is the alphabet soup of acronyms. RCA, RCM, FMEA, ODR, CMMS, EAM, BOM, KPI, MRO, PdM, PM, IIoT … The list goes on and on. The problem is that while many of these elements are critical to implementing a successful asset performance management (APM) initiative, it is overwhelming for those tasked with doing it at the plant level. There is a tendency to want to apply all these tools and technologies to all areas of the plant at the same time.
Anyone who has worked in a large industrial plant knows that reaction always takes precedence over proaction. I am not saying that is right, but it is a reality. The “failure of the day” always takes priority over longer-term improvement efforts. How many times do you come to work with a list of improvement objective for the plant, only to be thrown into some critical equipment failure that happened the night before. Therefore, we need to be practical in our approaches and expectations.
We often hear the adage; how do you eat an elephant? One bite at a time! We need to do the same when trying to implement a reliability initiative in a large production facility. I suggest a very simple model that encompasses all these critical elements in a practical set of work processes.
Strategize, Execute and Evaluate (Figure 1)!
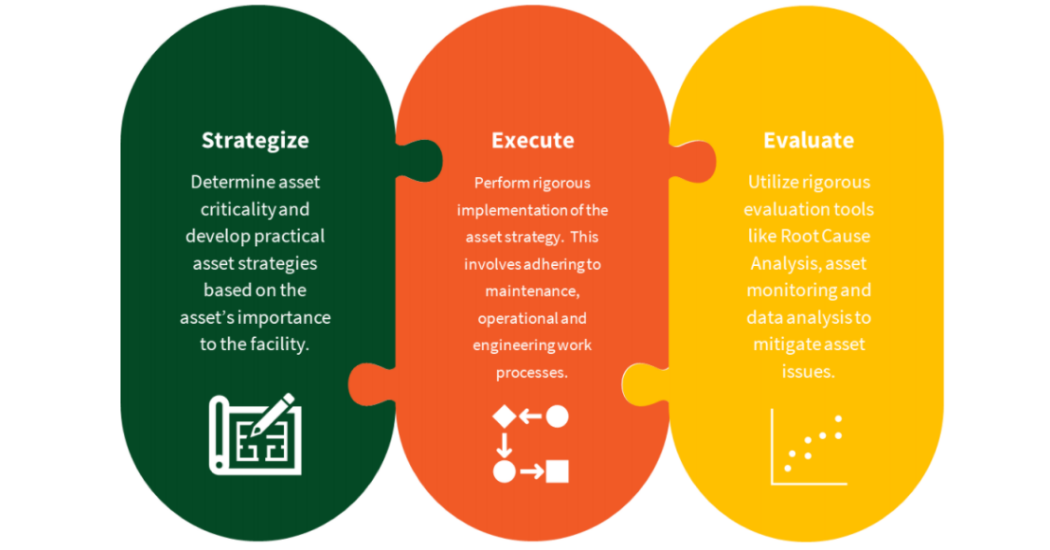
Figure 1: A Practical & Simple Reliability Work Process
When it comes to maintenance and reliability initiatives, many companies focus solely on the Execute phase. They implement asset management elements like a computerized maintenance management system (CMMS), invest in the planning and scheduling of work, spare parts (MRO) and the like. However, there is often little thought as to the strategy of what work to actually execute to reduce overall risk. What are the inspections, mitigating tasks, etc. that are needed to ensure reliable operation of the assets? On the back end, how do you know if your efforts are working and providing the desired results. What is the evaluation protocol used to measure the effectiveness of your work? It is the combination of these elements and the continuous improvement loop that makes it work.
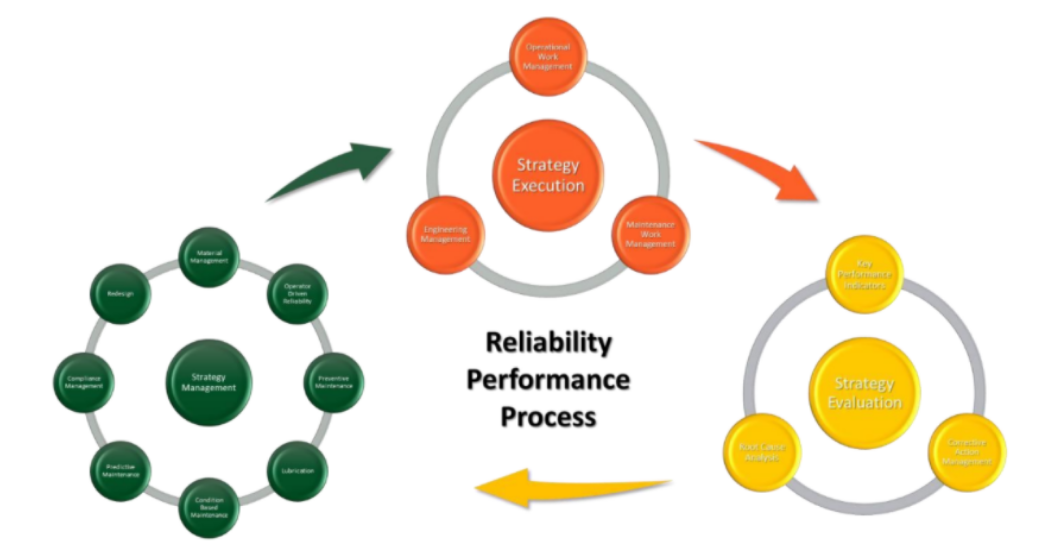
Figure 2. The Continuous Improvement Loop of a Practical Reliability Model
Let us drill into each stage for a clearer understanding of how they work and interact with one another
Strategize
Asset strategies are a key enabler for an effective reliability initiative. Plants have thousands of assets employed in the field. These range from large, fixed assets like tanks and pressure vessels, rotating assets like pumps and gearboxes down to tiny sensors and instruments that are monitoring the processes. Not all assets have the same importance or criticality to the facility. For example, a large turbine generator is highly critical to the operation because a failure could result in loss of power to many production assets in the facility. On the other hand, there might be some small water pumps that have redundant inline spares that will have little operational impact if they fail. So, our strategy for assets must coincide with the criticality of the assets themselves.
Criticality considers the consequences if something happens to the asset. A typical asset criticality evaluation will take the following variables into account:
- Safety
- Environmental
- Lost Production Opportunity
- Repair Cost
Using a combination of qualitative and quantitative measurements, an overall criticality rating can be applied to the broad population of production assets.
Once there is a basis for comparing criticality across assets, you can then determine the level of rigor to use in defining the strategy for those assets. Note, that a very small population of assets will be deemed highly critical. Maybe 10-15% at most. The bulk will have a medium level criticality and therefore a medium level of rigor in developing the strategy. There will then be a small number of assets that have virtually no effect on the operation. For these, we may use a basic
care/run to failure strategy because it might cost more to try and prevent a failure then just letting it fail.
There are many different types of tools and methodologies that can be used to develop a comprehensive asset strategy. Reliability Centered Maintenance (RCM), Failure Modes and Effects Analysis (FMEA), Asset Strategy Templates, Manufacturer Recommended Actions, etc. For assets in the High Criticality category, we might consider the more involved RCM or FMEA methodologies. For the bulk of the assets, we will use a more streamlined approach (see Figure 3) that might employ a combination of manufacturer recommendations and asset strategy templates built from internal subject matter experts (SME).

Figure 3. Asset Criticality Rankings
While there are many aspects to building an effective asset strategy, there are some core deliverables for any methodology that is used. The final output will be the specific actions that will be executed to eliminate or mitigate a failure mode (risk). For example, if bearing seizure is a failure mode for a large fan, vibration analysis, operator rounds, and lubrication management might be the specific actions deployed to mitigate that failure mode. More broadly, here are some of the basic deliverables for an asset strategy:
- Preventive Maintenance Actions (PM)
- Predictive Maintenance Actions (PdM)
- Operator Rounds/Operator Driven Reliability (ODR) Compliance Actions
- Operational Procedures (e.g., Startup and Shutdown Procedures, Lockout/Tagout Steps, etc.)
- Lubrication requirements
- Material Management (bill of materials, storeroom parts)
- Capital Improvements
To sum up, an asset strategy, select critical, yet manageable systems, and perform equipment strategies on the assets in that system. Define the failure modes (risks) and determine the proper mitigating tasks (PM, PdM, Lubrication, ODR, etc.). Ensure that all materials are defined and on the BOM and critical materials are in the storeroom and well maintained. Lastly, determine if capital improvements are required to get the asset/system to a level where it can reliably perform its intended function.
Execution
The execution of the strategy is where the rubber really hits the road. Without execution, strategies are just an academic exercise, and nothing will really improve. Work execution is typically performed within operations, maintenance and engineering. Tools like EAM, APM, process historians and many others are key enablers to making the process work. This is also where defined work processes for planning, scheduling, precision maintenance, lubrication, rebuild specifications and many others come into play.
For time-based repetitive work, the mitigating actions must be defined in the proper execution systems. For example, in most organizations, maintenance work does not take place without a work order. Most modern CMMS/EAM systems allow for the creation of maintenance plans. These plans are the triggers for executing the maintenance work in the field. Work Orders will be initiated into the proper backlog so that the work can be effectively planned and scheduled. However, good maintenance plans have the planning already built-in so the work order will be immediately ready to schedule.
For operational work, these tasks might be enabled through an Asset Performance Management (APM) system. For example, their rounds can be set up in the system so that the data can be collected on a mobile device and any follow-up actions can easily be addressed.
It is critically important to understand that any maintenance, operational or engineering work most have defined work processes so that everyone knows the process and the role they play within that process. Automation without efficient ingrained work processes is likely to cause more harm than good.
Evaluation
Finally, we need to evaluate to ensure that the deployed strategy is working. This can be done in a variety of ways. Metrics and KPI’s are a great way to measure performance of strategies. Reports from data systems to show whether the strategy tasks are being performed and at the proper frequency. With our assets getting smarter and smarter, we can use the power of IIoT, digital twins, and integrated asset health solutions to provide insight into how well our strategies are really working. One of the most powerful tools in our reliability toolbox is Root Cause Analysis (RCA).
We can also use our Root Cause Analysis (RCA) work process to uncover the causes of asset performance issues and update our equipment strategy when we find things like omitting a failure mode or one of our mitigating actions was the wrong frequency.
For all of this to work properly, it must be based on a solid foundation. Facility and Corporate Leaders must understand and support the reliability approach. For example, when a critical failure occurs, they should not only ask when we will be back up and running but why did it happen in the first place and what are we doing to prevent it in the future. Active engagement with leaders, engineers, operators and craftsmen is critical. Celebrate successes and encourage involvement from all levels. Continually communicate the message that reliable operations are key to business success. Much the same way that we constantly reinforce the importance of safety in all aspects of our work, we must have the same level of communication about reliability. You can never over-communicate the message!
In summary, there is no “easy button” for reliability improvement. We need to focus and to be “practical” in our efforts to implement a successful asset performance process. It is a long journey with many bumps in the road. However, if you stick with it and are always practical in your approach, you cannot help but to be overwhelmingly successful.
Ken is Managing Director of Prelical Solutions, LLC (www.prelical.com). His specialties include expertise in Root Cause Analysis (RCA), Reliability Analysis, FMEA, SAP PM Implementation and Utilization, GE Digital APM Solutions, Maintenance and Reliability Assessments, Certified Manufacturing Game® Facilitator, Certified Maintenance and Reliability Professional (SMRP/CMRP), Equipment Strategies, Operator Driven Reliability (ODR), Maintenance Work Management, Maintenance Budget Development and Management and Mobile Field Data Collection. Ken can be reached at Kenneth.Latino@prelical.com or info@prelical.com.


